Like many of our tech blog readers, Netflix is getting ready for AWS re:Invent in Las Vegas next week. Lots of Netflix engineers and recruiters will be in attendance, and we're looking forward to meeting and reconnecting with cloud enthusiasts and Netflix OSS users.
To make it a little easier to find our speakers at re:Invent, we're posting the schedule of Netflix talks here. We'll also have a booth on the expo floor and hope to see you there!
AES119 - Boosting Your Developers Productivity and Efficiency by Moving to a Container-Based Environment with Amazon ECS
Abstract: Increasing productivity and encouraging more efficient ways for development teams to work is top of mind for nearly every IT leader. In this session, Neil Hunt, Chief Product Officer at Netflix, will discuss why the company decided to introduce a container-based approach in order to speed development time, improve resource utilization, and simplify the developer experience. Learn about the company’s technical and business goals, technology choices and tradeoffs it had to make, and benefits of using Amazon ECS.
ARC204 - From Resilience to Ubiquity - #NetflixEverywhere Global Architecture
Abstract: Building and evolving a pervasive, global service requires a multi-disciplined approach that balances requirements with service availability, latency, data replication, compute capacity, and efficiency. In this session, we’ll follow the Netflix journey of failure, innovation, and ubiquity. We'll review the many facets of globalization and then delve deep into the architectural patterns that enable seamless, multi-region traffic management; reliable, fast data propagation; and efficient service infrastructure. The patterns presented will be broadly applicable to internet services with global aspirations.
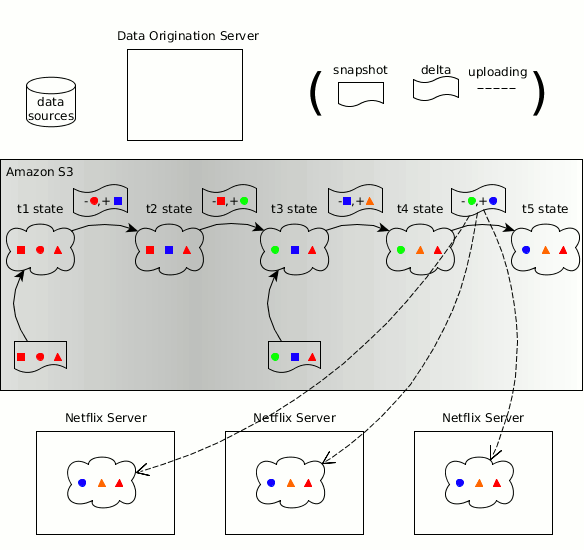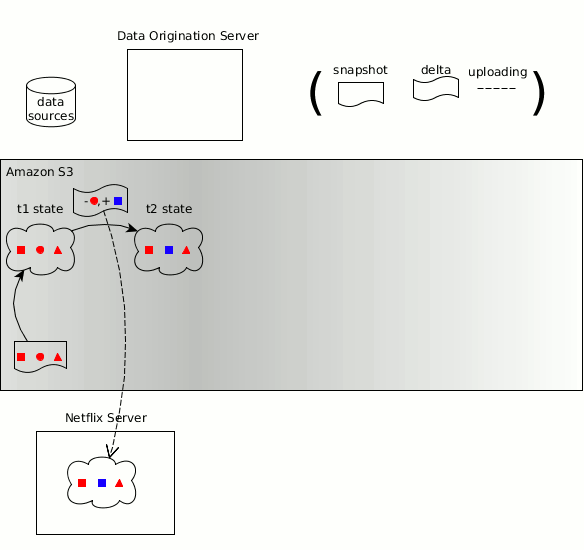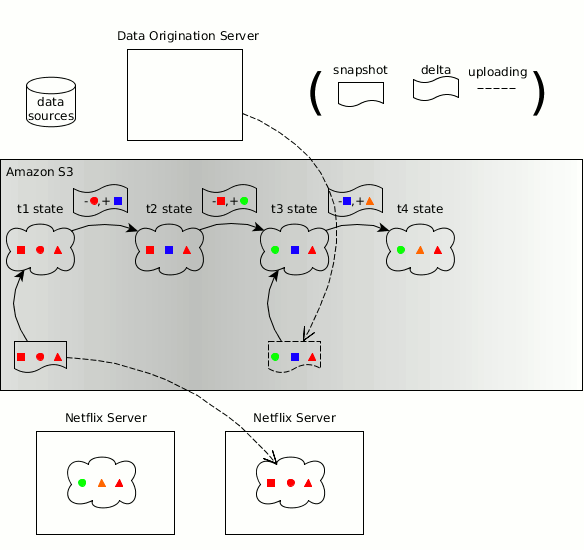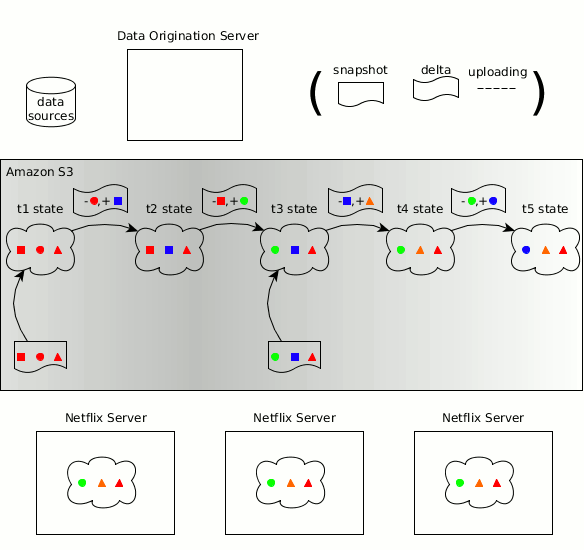
BDM306 - Netflix: Using Amazon S3 as the fabric of our big data ecosystem
Abstract: Amazon S3 is the central data hub for Netflix's big data ecosystem. We currently have over 1.5 billion objects and 60+ PB of data stored in S3. As we ingest, transform, transport, and visualize data, we find this data naturally weaving in and out of S3. Amazon S3 provides us the flexibility to use an interoperable set of big data processing tools like Spark, Presto, Hive, and Pig. It serves as the hub for transporting data to additional data stores / engines like Teradata, Redshift, and Druid, as well as exporting data to reporting tools like Microstrategy and Tableau. Over time, we have built an ecosystem of services and tools to manage our data on S3. We have a federated metadata catalog service that keeps track of all our data. We have a set of data lifecycle management tools that expire data based on business rules and compliance. We also have a portal that allows users to see the cost and size of their data footprint. In this talk, we’ll dive into these major uses of S3, as well as many smaller cases, where S3 smoothly addresses an important data infrastructure need. We will also provide solutions and methodologies on how you can build your own S3 big data hub.
CON313 - Netflix: Container Scheduling, Execution, and Integration with AWS
DEV209 - Another Day in the Life of a Netflix Engineer
DEV311 - Multi-Region Delivery Netflix Style
MBL204 - How Netflix Achieves Email Delivery at Global Scale with Amazon SES
NET304 - Moving Mountains: Netflix's Migration into VPC
SAC307 - The Psychology of Security Automation
STG306 - Tableau Rules of Engagement in the Cloud
To make it a little easier to find our speakers at re:Invent, we're posting the schedule of Netflix talks here. We'll also have a booth on the expo floor and hope to see you there!
AES119 - Boosting Your Developers Productivity and Efficiency by Moving to a Container-Based Environment with Amazon ECS
Wednesday, November 30 3:40pm (Executive Summit)
Neil Hunt, Chief Product Officer
ARC204 - From Resilience to Ubiquity - #NetflixEverywhere Global Architecture
Tuesday, November 29 9:30am
Thursday, December 1 12:30pm
Coburn Watson, Director, Performance and Reliability
Tuesday, November 29, 5:30pm
Wednesday, November 30, 12:30pm
Eva Tse, Director, Big Data Platform
Kurt Brown, Director, Data Platform
CON313 - Netflix: Container Scheduling, Execution, and Integration with AWS
Thursday, December 1, 2:00pm
Andrew Spyker, Manager, Netflix Container Cloud
Abstract: Members from over all over the world streamed over forty-two billion hours of Netflix content last year. Various Netflix batch jobs and an increasing number of service applications use containers for their processing. In this session, Netflix presents a deep dive on the motivations and the technology powering container deployment on top of Amazon Web Services. The session covers our approach to resource management and scheduling with the open source Fenzo library, along with details of how we integrate Docker and Netflix container scheduling running on AWS. We cover the approach we have taken to deliver AWS platform features to containers such as IAM roles, VPCs, security groups, metadata proxies, and user data. We want to take advantage of native AWS container resource management using Amazon ECS to reduce operational responsibilities. We are delivering these integrations in collaboration with the Amazon ECS engineering team. The session also shares some of the results so far, and lessons learned throughout our implementation and operations.
Abstract: Members from over all over the world streamed over forty-two billion hours of Netflix content last year. Various Netflix batch jobs and an increasing number of service applications use containers for their processing. In this session, Netflix presents a deep dive on the motivations and the technology powering container deployment on top of Amazon Web Services. The session covers our approach to resource management and scheduling with the open source Fenzo library, along with details of how we integrate Docker and Netflix container scheduling running on AWS. We cover the approach we have taken to deliver AWS platform features to containers such as IAM roles, VPCs, security groups, metadata proxies, and user data. We want to take advantage of native AWS container resource management using Amazon ECS to reduce operational responsibilities. We are delivering these integrations in collaboration with the Amazon ECS engineering team. The session also shares some of the results so far, and lessons learned throughout our implementation and operations.
Wednesday, November 30, 4:00pm
Dave Hahn, Senior SRE
Abstract: Netflix is big. Really big. You just won't believe how vastly, hugely, mind-bogglingly big it is. Netflix is a large, ever changing, ecosystem system serving million of customers across the globe through cloud-based systems and a globally distributed CDN. This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We’ll talk about:
- The Bits - The technologies used to run a global streaming company
- Making the Bits Bigger - Scaling at scale
- Keeping an Eye Out - Billions of metrics
- Break all the Things - Chaos in production is key
- DevOps - How culture affects your velocity and uptime
DEV311 - Multi-Region Delivery Netflix Style
Thursday, December 1, 1:00pm
Andrew Glover, Engineering Manager
Abstract: Netflix rapidly deploys services across multiple AWS accounts and regions over 4,000 times a day. We’ve learned many lessons about reliability and efficiency. What’s more, we’ve built sophisticated tooling to facilitate our growing global footprint. In this session, you’ll learn about how Netflix confidently delivers services on a global scale and how, using best practices combined with freely available open source software, you can do the same.
Abstract: Netflix rapidly deploys services across multiple AWS accounts and regions over 4,000 times a day. We’ve learned many lessons about reliability and efficiency. What’s more, we’ve built sophisticated tooling to facilitate our growing global footprint. In this session, you’ll learn about how Netflix confidently delivers services on a global scale and how, using best practices combined with freely available open source software, you can do the same.
MBL204 - How Netflix Achieves Email Delivery at Global Scale with Amazon SES
Tuesday, November 29, 10:00am
Devika Chawla, Engineering Director
Abstract: Companies around the world are using Amazon Simple Email Service (Amazon SES) to send millions of emails to their customers every day, and scaling linearly, at cost. In this session, you learn how to use the scalable and reliable infrastructure of Amazon SES. In addition, Netflix talks about their advanced Messaging program, their challenges, how SES helped them with their goals, and how they architected their solution for global scale and deliverability.
Abstract: Companies around the world are using Amazon Simple Email Service (Amazon SES) to send millions of emails to their customers every day, and scaling linearly, at cost. In this session, you learn how to use the scalable and reliable infrastructure of Amazon SES. In addition, Netflix talks about their advanced Messaging program, their challenges, how SES helped them with their goals, and how they architected their solution for global scale and deliverability.
NET304 - Moving Mountains: Netflix's Migration into VPC
Thursday, December 1, 3:30pm
Andrew Braham, Manager, Cloud Network Engineering
Laurie Ferioli, Senior Program Manager
Abstract: Netflix was one of the earliest AWS customers with such large scale. By 2014, we were running hundreds of applications in Amazon EC2. That was great, until we needed to move to VPC. Given our scale, uptime requirements, and the decentralized nature of how we manage our production environment, the VPC migration (still ongoing) presented particular challenges for us and for AWS as it sought to support our move. In this talk, we discuss the starting state, our requirements and the operating principles we developed for how we wanted to drive the migration, some of the issues we ran into, and how the tight partnership with AWS helped us migrate from an EC2-Classic platform to an EC2-VPC platform.
Abstract: Netflix was one of the earliest AWS customers with such large scale. By 2014, we were running hundreds of applications in Amazon EC2. That was great, until we needed to move to VPC. Given our scale, uptime requirements, and the decentralized nature of how we manage our production environment, the VPC migration (still ongoing) presented particular challenges for us and for AWS as it sought to support our move. In this talk, we discuss the starting state, our requirements and the operating principles we developed for how we wanted to drive the migration, some of the issues we ran into, and how the tight partnership with AWS helped us migrate from an EC2-Classic platform to an EC2-VPC platform.
SAC307 - The Psychology of Security Automation
Thursday, December 1, 12:30pm
Friday, December 2, 11:00am
Jason Chan, Director, Cloud Security
Abstract: Historically, relationships between developers and security teams have been challenging. Security teams sometimes see developers as careless and ignorant of risk, while developers might see security teams as dogmatic barriers to productivity. Can technologies and approaches such as the cloud, APIs, and automation lead to happier developers and more secure systems? Netflix has had success pursuing this approach, by leaning into the fundamental cloud concept of self-service, the Netflix cultural value of transparency in decision making, and the engineering efficiency principle of facilitating a “paved road.”
This session explores how security teams can use thoughtful tools and automation to improve relationships with development teams while creating a more secure and manageable environment. Topics include Netflix’s approach to IAM entity management, Elastic Load Balancing and certificate management, and general security configuration monitoring.
Jason Chan, Director, Cloud Security
Abstract: Historically, relationships between developers and security teams have been challenging. Security teams sometimes see developers as careless and ignorant of risk, while developers might see security teams as dogmatic barriers to productivity. Can technologies and approaches such as the cloud, APIs, and automation lead to happier developers and more secure systems? Netflix has had success pursuing this approach, by leaning into the fundamental cloud concept of self-service, the Netflix cultural value of transparency in decision making, and the engineering efficiency principle of facilitating a “paved road.”
This session explores how security teams can use thoughtful tools and automation to improve relationships with development teams while creating a more secure and manageable environment. Topics include Netflix’s approach to IAM entity management, Elastic Load Balancing and certificate management, and general security configuration monitoring.
Thursday, December 1, 1:00pm
Srikanth Devidi, Senior Data Engineer
Albert Wong, Enterprise Reporting Platform Manager
Abstract: You have billions of events in your fact table, all of it waiting to be visualized. Enter Tableau… but wait: how can you ensure scalability and speed with your data in Amazon S3, Spark, Amazon Redshift, or Presto? In this talk, you’ll hear how Albert Wong and Srikanth Devidi at Netflix use Tableau on top of their big data stack. Albert and Srikanth also show how you can get the most out of a massive dataset using Tableau, and help guide you through the problems you may encounter along the way.
Abstract: You have billions of events in your fact table, all of it waiting to be visualized. Enter Tableau… but wait: how can you ensure scalability and speed with your data in Amazon S3, Spark, Amazon Redshift, or Presto? In this talk, you’ll hear how Albert Wong and Srikanth Devidi at Netflix use Tableau on top of their big data stack. Albert and Srikanth also show how you can get the most out of a massive dataset using Tableau, and help guide you through the problems you may encounter along the way.
By Jason Chan