At Netflix we care about video quality, and we care about measuring video quality accurately at scale. Our method, Video Multimethod Assessment Fusion (VMAF), seeks to reflect the viewer’s perception of our streaming quality. We are open-sourcing this tool and invite the research community to collaborate with us on this important project.
Our Quest for High Quality Video
We strive to provide our members with a great viewing experience: smooth video playback, free of annoying picture artifacts. A significant part of this endeavor is delivering video streams with the best perceptual quality possible, given the constraints of the network bandwidth and viewing device. We continuously work towards this goal through multiple efforts.
First, we innovate in the area of video encoding. Streaming video requires compression using standards, such as H.264/AVC, HEVC and VP9, in order to stream at reasonable bitrates. When videos are compressed too much or improperly, these techniques introduce quality impairments, known as compression artifacts. Experts refer to them as “blocking”, “ringing” or “mosquito noise”, but for the typical viewer, the video just doesn’t look right. For this reason, we regularly compare codec vendors on compression efficiency, stability and performance, and integrate the best solutions in the market. We evaluate the different video coding standards to ensure that we remain at the cutting-edge of compression technology. For example, we run comparisons among H.264/AVC, HEVC and VP9, and in the near future we will experiment on the next-generation codecs developed by the Alliance for Open Media (AOM) and the Joint Video Exploration Team (JVET). Even within established standards we continue to experiment on recipe decisions (see Per-Title Encoding Optimization project) and rate allocation algorithms to fully utilize existing toolsets.
We encode the Netflix video streams in a distributed cloud-based media pipeline, which allows us to scale to meet the needs of our business. To minimize the impact of bad source deliveries, software bugs and the unpredictability of cloud instances (transient errors), we automate quality monitoring at various points in our pipeline. Through this monitoring, we seek to detect video quality issues at ingest and at every transform point in our pipeline.
Finally, as we iterate in various areas of the Netflix ecosystem (such as the adaptive streaming or content delivery network algorithms) and run A/B tests, we work to ensure that video quality is maintained or improved by the system refinements. For example, an improvement in the adaptive streaming algorithm that is aimed to reduce playback start delay or re-buffers should not degrade overall video quality in a streaming session.
All of the challenging work described above hinges on one fundamental premise: that we can accurately and efficiently measure the perceptual quality of a video stream at scale. Traditionally, in video codec development and research, two methods have been extensively used to evaluate video quality: 1) Visual subjective testing and 2) Calculation of simple metrics such as PSNR, or more recently, SSIM [1].
Without doubt, manual visual inspection is operationally and economically infeasible
for the throughput of our production, A/B test monitoring and encoding research experiments. Measuring image quality is an old problem, to which a number of simple and practical solutions have been proposed. Mean-squared-error (MSE), Peak-signal-to-noise-ratio (PSNR) and Structural Similarity Index (SSIM) are examples of metrics originally designed for images and later extended to video. These metrics are often used within codecs (“in-loop”) for optimizing coding decisions and for reporting the final quality of encoded video. Although researchers and engineers in the field are well-aware that PSNR does not consistently reflect human perception, it remains the de facto standard for codec comparisons and codec standardization work.
Building A Netflix-Relevant Dataset
To evaluate video quality assessment algorithms, we take a data-driven approach. The first step is to gather a dataset that is relevant to our use case. Although there are publicly available databases for designing and testing video quality metrics, they lack the diversity in content that is relevant to practical streaming services such as Netflix. Many of them are no longer state-of-the-art in terms of the quality of the source and encodes; for example, they contain standard definition (SD) content and cover older compression standards only. Furthermore, since the problem of assessing video quality is far more general than measuring compression artifacts, the existing databases seek to capture a wider range of impairments caused not only by compression, but also by transmission losses, random noise and geometric transformations. For example, real-time transmission of surveillance footage of typically black and white, low-resolution video (640x480) exhibits a markedly different viewing experience than that experienced when watching one’s favorite Netflix show in a living room.
Netflix's streaming service presents a unique set of challenges as well as opportunities for designing a perceptual metric that accurately reflects streaming video quality. For example:
Video source characteristics. Netflix carries a vast collection of movies and TV shows, which exhibit diversity in genre such as kids content, animation, fast-moving action movies, documentaries with raw footage, etc. Furthermore, they also exhibit diverse low-level source characteristics, such as film-grain, sensor noise, computer-generated textures, consistently dark scenes or very bright colors. Many of the quality metrics developed in the past have not been tuned to accommodate this huge variation in source content. For example, many of the existing databases lack animation content and most don’t take into account film grain, a signal characteristic that is very prevalent in professional entertainment content.
Source of artifacts. As Netflix video streams are delivered using the robust Transmission Control Protocol (TCP), packet losses and bit errors are never sources of visual impairments. That leaves two types of artifacts in the encoding process which will ultimately impact the viewer's quality of experience (QoE): compression artifacts (due to lossy compression) and scaling artifacts (for lower bitrates, video is downsampled before compression, and later upsampled on the viewer’s device). By tailoring a quality metric to only cover compression and scaling artifacts, trading generality for precision, its accuracy is expected to outperform a general-purpose one.
To build a dataset more tailored to the Netflix use case, we selected a sample of 34 source clips (also called reference videos), each 6 seconds long, from popular TV shows and movies from the Netflix catalog and combined them with a selection of publicly available clips. The source clips covered a wide range of high-level features (animation, indoor/outdoor, camera motion, face close-up, people, water, obvious salience, number of objects) and low level characteristics (film grain noise, brightness, contrast, texture, motion, color variance, color richness, sharpness). Using the source clips, we encoded H.264/AVC video streams at resolutions ranging from 384x288 to 1920x1080 and bitrates from 375 kbps to 20,000 kbps, resulting in about 300 distorted videos. This sweeps a broad range of video bitrates and resolutions to reflect the widely varying network conditions of Netflix members.
We then ran subjective tests to determine how non-expert observers would score the impairments of an encoded video with respect to the source clip. In standardized subjective testing, the methodology we used is referred to as the Double Stimulus Impairment Scale (DSIS) method. The reference and distorted videos were displayed sequentially on a consumer-grade TV, with controlled ambient lighting (as specified in recommendation ITU-R BT.500-13 [2]). If the distorted video was encoded at a smaller resolution than the reference, it was upscaled to the source resolution before it was displayed on the TV. The observer sat on a couch in a living room-like environment and was asked to rate the impairment on a scale of 1 (very annoying) to 5 (not noticeable).The scores from all observers were combined to generate a Differential Mean Opinion Score or DMOS for each distorted video and normalized in the range 0 to 100, with the score of 100 for the reference video. The set of reference videos, distorted videos and DMOS scores from observers will be referred to in this article as the NFLX Video Dataset.
Traditional Video Quality Metrics
How do the traditional, widely-used video quality metrics correlate to the “ground-truth” DMOS scores for the NFLX Video Dataset?
A Visual Example
Above, we see portions of still frames captured from 4 different distorted videos; the two videos on top reported a PSNR value of about 31 dB, while the bottom two reported a PSNR value of about 34 dB. Yet, one can barely notice the difference on the “crowd” videos, while the difference is much more clear on the two “fox” videos. Human observers confirm it by rating the two “crowd” videos as having a DMOS score of 82 (top) and 96 (bottom), while rating the two “fox” videos with DMOS scores of 27 and 58, respectively.
Detailed Results
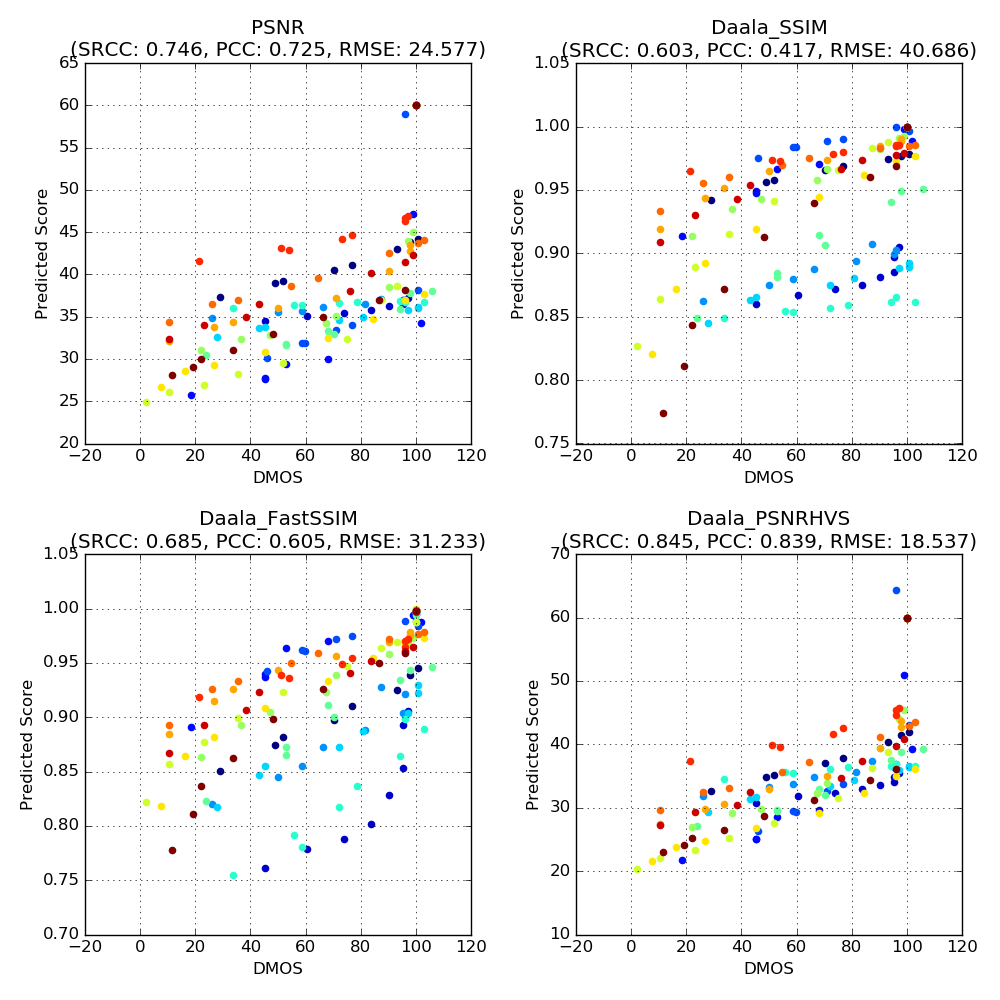
The graphs below are scatter plots showing the observers’ DMOS on the x-axis and the predicted score from different quality metrics on the y-axis. These plots were obtained from a selected subset of the NFLX Video Dataset, which we label as NFLX-TEST (see next section for details). Each point represents one distorted video. We plot the results for four quality metrics:
PSNR for luminance component SSIM [1]
Multiscale FastSSIM [3]
PSNR-HVS [4]
More details on SSIM, Multiscale FastSSIM and PSNR-HVS can be found in the publications listed in the Reference section. For these three metrics we used the implementation in the Daala code base [5] so the titles in subsequent graphs are prefixed with “Daala”.
Note: The points with the same color correspond to distorted videos stemming from the same reference video. Due to subject variability and reference video normalization to 100, some DMOS scores can exceed 100.
It can be seen from the graphs that these metrics fail to provide scores that consistently predict the DMOS ratings from observers. For example, focusing on the PSNR graph on the upper left corner, for PSNR values around 35 dB, the “ground-truth” DMOS values range anywhere from 10 (impairments are annoying) to 100 (impairments are imperceptible). Similar conclusions can be drawn for the SSIM and multiscale FastSSIM metrics, where a score close to 0.90 can correspond to DMOS values from 10 to 100. Above each plot, we report the Spearman’s rank correlation coefficient (SRCC), the Pearson product-moment correlation coefficient (PCC) and the root-mean-squared-error (RMSE) figures for each of the metrics, calculated after a non-linear logistic fitting, as outlined in Annex 3.1 of ITU-R BT.500-13 [2]. SRCC and PCC values closer to 1.0 and RMSE values closer to zero are desirable. Among the four metrics, PSNR-HVS demonstrates the best SRCC, PCC and RMSE values, but is still lacking in prediction accuracy.
In order to achieve meaningful performance across wide variety of content, a metric should exhibit good relative quality scores, i.e., a delta in the metric should provide information about the delta in perceptual quality. In the graphs below, we select three typical reference videos, a high-noise video, a CG animation and a TV drama, and plot the predicted score vs. DMOS of the different distorted videos for each. To be effective as a relative quality score, a constant slope across different clips within the same range of the quality curve is desirable. For example, referring to the PSNR plot below, in the range 34 dB to 36 dB, a change in PSNR of about 2 dB for TV drama corresponds to a DMOS change of about 50 (50 to 100) but a similar 2 dB change in the same range for the CG animation corresponds to less than 20 (40 to 60) change in DMOS. While SSIM and FastSSIM exhibit more consistent slopes for CG animation and TV drama clips, their performance is still lacking.
![blogpost_others2.png]()
In conclusion, we see that the traditional metrics do not work well for our content. To address this issue we adopted a machine-learning based model to design a metric that seeks to reflect human perception of video quality. This metric is discussed in the following section.
Our Method: Video Multimethod Assessment Fusion (VMAF)
Building on our research collaboration with Prof. C.-C. J. Kuo and his group at the University of Southern California [6][7], we developed Video Multimethod Assessment Fusion, or VMAF, that predicts subjective quality by combining multiple elementary quality metrics. The basic rationale is that each elementary metric may have its own strengths and weaknesses with respect to the source content characteristics, type of artifacts, and degree of distortion. By ‘fusing’ elementary metrics into a final metric using a machine-learning algorithm - in our case, a Support Vector Machine (SVM) regressor - which assigns weights to each elementary metric, the final metric could preserve all the strengths of the individual metrics, and deliver a more accurate final score. The machine-learning model is trained and tested using the opinion scores obtained through a subjective experiment (in our case, the NFLX Video Dataset).
The current version of the VMAF algorithm and model (denoted as VMAF 0.3.1), released as part of the VMAF Development Kit open source software, uses the following elementary metrics fused by Support Vector Machine (SVM) regression [8]:
Visual Information Fidelity (VIF) [9]. VIF is a well-adopted image quality metric based on the premise that quality is complementary to the measure of information fidelity loss. In its original form, the VIF score is measured as a loss of fidelity combining four scales. In VMAF, we adopt a modified version of VIF where the loss of fidelity in each scale is included as an elementary metric.
Detail Loss Metric (DLM) [10]. DLM is an image quality metric based on the rationale of separately measuring the loss of details which affects the content visibility, and the redundant impairment which distracts viewer attention. The original metric combines both DLM and additive impairment measure (AIM) to yield a final score. In VMAF, we only adopt the DLM as an elementary metric. Particular care was taken for special cases, such as black frames, where numerical calculations for the original formulation break down.
VIF and DLM are both image quality metrics. We further introduce the following simple feature to account for the temporal characteristics of video:
Motion. This is a simple measure of the temporal difference between adjacent frames. This is accomplished by calculating the average absolute pixel difference for the luminance component.
These elementary metrics and features were chosen from amongst other candidates through iterations of testing and validation.
We compare the accuracy of VMAF to the other quality metrics described above. To avoid unfairly overfitting VMAF to the dataset, we first divide the NFLX Dataset into two subsets, referred to as NFLX-TRAIN and NFLX-TEST. The two sets have non-overlapping reference clips. The SVM regressor is then trained with the NFLX-TRAIN dataset, and tested on NFLX-TEST. The plots below show the performance of the VMAF metric on the NFLX-TEST dataset and on the selected reference clips (high-noise video, a CG animation and TV drama). For ease of comparison, we repeat the plots for PSNR-HVS, the best performing metric from the earlier section. It is clear that VMAF performs appreciably better.![vmaf_psnrhvs.png]()
![vmaf_psnrhvs_3content.png]()
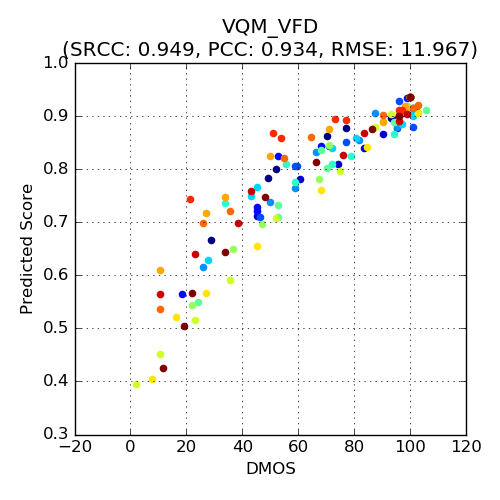
We also compare VMAF to the Video Quality Model with Variable Frame Delay (VQM-VFD) [11], considered by many as state of the art in the field. VQM-VFD is an algorithm that uses a neural network model to fuse low-level features into a final metric. It is similar to VMAF in spirit, except that it extracts features at lower levels such as spatial and temporal gradients. It is clear that VQM-VFD performs close to VMAF on the NFLX-TEST dataset. Since the VMAF approach allows for incorporation of new elementary metrics into its framework, VQM-VFD could serve as an elementary metric for VMAF as well.
The table below lists the performance, as measured by the SRCC, PCC and RMSE figures, of the VMAF model after fusing different combinations of the individual elementary metrics on the NFLX-TEST dataset, as well as the final performance of VMAF 0.3.1. We also list the performance of VMAF augmented with VQM-VFD. The results justify our premise that an intelligent fusion of high-performance quality metrics results in an increased correlation with human perception.
NFLX-TEST dataset
| SRCC | PCC | RMSE |
VIF | 0.883 | 0.859 | 17.409 |
ADM | 0.948 | 0.954 | 9.849 |
VIF+ADM | 0.953 | 0.956 | 9.941 |
VMAF 0.3.1 (VIF+ADM +MOTION) | 0.953 | 0.963 | 9.277 |
VQM-VFD | 0.949 | 0.934 | 11.967 |
VMAF 0.3.1 +VQM-VFD | 0.959 | 0.965 | 9.159 |
Summary of Results
In the tables below we summarize the SRCC, PCC and RMSE of the different metrics discussed earlier, on the NLFX-TEST dataset and three popular public datasets: the VQEG HD (vqeghd3 collection only) [12], the LIVE Video Database [13] and the LIVE Mobile Video Database [14]. The results show that VMAF 0.3.1 outperforms other metrics in all but the LIVE dataset, where it still offers competitive performance compared to the best-performing VQM-VFD. Since VQM-VFD demonstrates good correlation across the four datasets, we are experimenting with VQM-VFD as an elementary metric for VMAF; although it is not part of the open source release VMAF 0.3.1, it may be integrated in subsequent releases.
NFLX-TEST dataset
| SRCC | PCC | RMSE |
PSNR | 0.746 | 0.725 | 24.577 |
SSIM | 0.603 | 0.417 | 40.686 |
FastSSIM | 0.685 | 0.605 | 31.233 |
PSNR-HVS | 0.845 | 0.839 | 18.537 |
VQM-VFD | 0.949 | 0.934 | 11.967 |
VMAF 0.3.1 | 0.953 | 0.963 | 9.277 |
LIVE dataset*
| SRCC | PCC | RMSE |
PSNR | 0.416 | 0.394 | 16.934 |
SSIM | 0.658 | 0.618 | 12.340 |
FastSSIM | 0.566 | 0.561 | 13.691 |
PSNR-HVS | 0.589 | 0.595 | 13.213 |
VQM-VFD | 0.763 | 0.767 | 9.897 |
VMAF 0.3.1 | 0.690 | 0.655 | 12.180 |
*For compression-only impairments (H.264/AVC and MPEG-2 Video)
VQEGHD3 dataset*
| SRCC | PCC | RMSE |
PSNR | 0.772 | 0.759 | 0.738 |
SSIM | 0.856 | 0.834 | 0.621 |
FastSSIM | 0.910 | 0.922 | 0.415 |
PSNR-HVS | 0.858 | 0.850 | 0.580 |
VQM-VFD | 0.925 | 0.924 | 0.420 |
VMAF 0.3.1 | 0.929 | 0.939 | 0.372 |
*For source content SRC01 to SRC09 and streaming-relevant impairments HRC04, HRC07, and HRC16 to HRC21
LIVE Mobile dataset
| SRCC | PCC | RMSE |
PSNR | 0.632 | 0.643 | 0.850 |
SSIM | 0.664 | 0.682 | 0.831 |
FastSSIM | 0.747 | 0.745 | 0.718 |
PSNR-HVS | 0.703 | 0.726 | 0.722 |
VQM-VFD | 0.770 | 0.795 | 0.639 |
VMAF 0.3.1 | 0.872 | 0.905 | 0.401 |
VMAF Development Kit (VDK) Open Source Package
To deliver high-quality video over the Internet, we believe that the industry needs good perceptual video quality metrics that are practical to use and easy to deploy at scale. We have developed VMAF to help us address this need. Today, we are open-sourcing the VMAF Development Kit (VDK 1.0.0) package on Github under Apache License Version 2.0. By open-sourcing the VDK, we hope it can evolve over time to yield improved performance.
The feature extraction (including elementary metric calculation) portion in the VDK core is computationally-intensive and so it is written in C for efficiency. The control code is written in Python for fast prototyping.
The package comes with a simple command-line interface to allow a user to run VMAF in single mode (run_vmaf command) or in batch mode (run_vmaf_in_batch command, which optionally enables parallel execution). Furthermore, as feature extraction is the most expensive operation, the user can also store the feature extraction results in a datastore to reuse them later.
The package also provides a framework for further customization of the VMAF model based on:
The video dataset it is trained on
The elementary metrics and other features to be used
The regressor and its hyper-parameters
The command run_training takes in three configuration files: a dataset file, which contains information on the training dataset, a feature parameter file and a regressor model parameter file (containing the regressor hyper-parameters). Below is sample code that defines a dataset, a set of selected features, the regressor and its hyper-parameters.
##### define a dataset #####
dataset_name = 'example'
yuv_fmt = 'yuv420p'
width = 1920
height = 1080
ref_videos = [
{'content_id':0, 'path':'checkerboard.yuv'},
{'content_id':1, 'path':'flat.yuv'},
]
dis_videos = [
{'content_id':0, 'asset_id': 0, 'dmos':100, 'path':'checkerboard.yuv'}, # ref
{'content_id':0, 'asset_id': 1, 'dmos':50, 'path':'checkerboard_dis.yuv'},
{'content_id':1, 'asset_id': 2, 'dmos':100, 'path':'flat.yuv'}, # ref
{'content_id':1, 'asset_id': 3, 'dmos':80, 'path':'flat_dis.yuv'},
]
##### define features #####
feature_dict = {
# VMAF_feature/Moment_feature are the aggregate features
# motion, adm2, dis1st are the atom features
'VMAF_feature':['motion', 'adm2'],
'Moment_feature':['dis1st'], # 1st moment on dis video
}
##### define regressor and hyper-parameters #####
model_type = "LIBSVMNUSVR" # libsvm NuSVR regressor
model_param_dict = {
# ==== preprocess: normalize each feature ==== #
'norm_type':'clip_0to1', # rescale to within [0, 1]
# ==== postprocess: clip final quality score ==== #
'score_clip':[0.0, 100.0], # clip to within [0, 100]
# ==== libsvmnusvr parameters ==== #
'gamma':0.85, # selected
'C':1.0, # default
'nu':0.5, # default
'cache_size':200 # default
}
Finally, the FeatureExtractor base class can be extended to develop a customized VMAF algorithm. This can be accomplished by experimenting with other available elementary metrics and features, or inventing new ones. Similarly, the TrainTestModel base class can be extended in order to test other regression models. Please refer to CONTRIBUTING.md for more details. A user could also experiment with alternative machine learning algorithms using existing open-source Python libraries, such as scikit-learn [15], cvxopt [16], or tensorflow [17]. An example integration of scikit-learn’s random forest regressor is included in the package.
The VDK package includes the VMAF 0.3.1 algorithm with selected features and a trained SVM model based on subjective scores collected on the NFLX Video Dataset. We also invite the community to use the software package to develop improved features and regressors for the purpose of perceptual video quality assessment. We encourage users to test VMAF 0.3.1 on other datasets, and help improve it for our use case and potentially extend it to other use cases.
Our Open Questions on Quality Assessment
Viewing conditions. Netflix supports thousands of active devices covering smart TV’s, game consoles, set-top boxes, computers, tablets and smartphones, resulting in widely varying viewing conditions for our members. The viewing set-up and display can significantly affect perception of quality. For example, a Netflix member watching a 720p movie encoded at 1 Mbps on a 4K 60-inch TV may have a very different perception of the quality of that same stream if it were instead viewed on a 5-inch smartphone. The current NFLX Video Dataset covers a single viewing condition -- TV viewing at a standardized distance. To augment VMAF, we are conducting subjective tests in other viewing conditions. With more data, we can generalize the algorithm such that viewing conditions (display size, distance from screen, etc.) can be inputs to the regressor.
Temporal pooling. Our current VMAF implementation calculates quality scores on a per-frame basis. In many use-cases, it is desirable to temporally pool these scores to return a single value as a summary over a longer period of time. For example, a score over a scene, a score over regular time segments, or a score for an entire movie is desirable. Our current approach is a simple temporal pooling that takes the arithmetic mean of the per-frame values. However, this method has the risk of “hiding” poor quality frames. A pooling algorithm that gives more weight to lower scores may be more accurate towards human perception. A good pooling mechanism is especially important when using the summary score to compare encodes of differing quality fluctuations among frames or as the target metric when optimizing an encode or streaming session. A perceptually accurate temporal pooling mechanism for VMAF and other quality metrics remains an open and challenging problem.
A consistent metric. Since VMAF incorporates full-reference elementary metrics, VMAF is highly dependent on the quality of the reference. Unfortunately, the quality of video sources may not be consistent across all titles in the Netflix catalog. Sources come into our system at resolutions ranging from SD to 4K. Even at the same resolution, the best source available may suffer from certain video quality impairments. Because of this, it can be inaccurate to compare (or summarize) VMAF scores across different titles. For example, when a video stream generated from an SD source achieves a VMAF score of 99 (out of 100), it by no means has the same perceptual quality as a video encoded from an HD source with the same score of 99. For quality monitoring, it is highly desirable that we can calculate absolute quality scores that are consistent across sources. After all, when viewers watch a Netflix show, they do not have any reference, other than the picture delivered to their screen. We would like to have an automated way to predict what opinion they form about the quality of the video delivered to them, taking into account all factors that contributed to the final presented video on that screen.
Summary
We have developed VMAF 0.3.1 and the VDK 1.0.0 software package to aid us in our work to deliver the best quality video streams to our members. Our team uses it everyday in evaluating video codecs and encoding parameters and strategies, as part of our continuing pursuit of quality. VMAF, together with other metrics, have been integrated into our encoding pipeline to improve on our automated QC. We are in the early stages of using VMAF as one of the client-side metrics to monitor system-wide A/B tests.
Improving video compression standards and making smart decisions in practical encoding systems is very important in today’s Internet landscape. We believe that using the traditional metrics - metrics that do not always correlate with human perception - can hinder real advancements in video coding technology. However, always relying on manual visual testing is simply infeasible. VMAF is our attempt to address this problem, using samples from our content to help design and validate the algorithms. Similar to how the industry works together in developing new video standards, we invite the community to openly collaborate on improving video quality measures, with the ultimate goal of more efficient bandwidth usage and visually pleasing video for all.
Acknowledgments
We would like to acknowledge the following individuals for their help with the VMAF project: Joe Yuchieh Lin, Eddy Chi-Hao Wu, Professor C.-C Jay Kuo (University of Southern California), Professor Patrick Le Callet (Université de Nantes) and Todd Goodall.
References
[1] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image Quality Assessment: From Error Visibility to Structural Similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, Apr. 2004.
[3] M.-J. Chen and A. C. Bovik, “Fast Structural Similarity Index Algorithm,” Journal of Real-Time Image Processing, vol. 6, no. 4, pp. 281–287, Dec. 2011.
[4] N. Ponomarenko, F. Silvestri, K. Egiazarian, M. Carli, J. Astola, and V. Lukin, “On Between-coefficient Contrast Masking of DCT Basis Functions,” in Proceedings of the 3 rd International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM ’07), Scottsdale, Arizona, Jan. 2007.
[6] T.-J. Liu, J. Y. Lin, W. Lin, and C.-C. J. Kuo, “Visual Quality Assessment: Recent Developments, Coding Applications and Future Trends,” APSIPA Transactions on Signal and Information Processing, 2013.
[7] J. Y. Lin, T.-J. Liu, E. C.-H. Wu, and C.-C. J. Kuo, “A Fusion-based Video Quality Assessment (FVQA) Index,” APSIPA Transactions on Signal and Information Processing, 2014.
[8] C.Cortes and V.Vapnik, “Support-Vector Networks,” Machine Learning, vol. 20, no. 3, pp. 273–297, 1995.
[9] H. Sheikh and A. Bovik, “Image Information and Visual Quality,” IEEE Transactions on Image Processing, vol. 15, no. 2, pp. 430–444, Feb. 2006.
[10] S. Li, F. Zhang, L. Ma, and K. Ngan, “Image Quality Assessment by Separately Evaluating Detail Losses and Additive Impairments,” IEEE Transactions on Multimedia, vol. 13, no. 5, pp. 935–949, Oct. 2011.
[11] S. Wolf and M. H. Pinson, “Video Quality Model for Variable Frame Delay (VQM_VFD),” U.S. Dept. Commer., Nat. Telecommun. Inf. Admin., Boulder, CO, USA, Tech. Memo TM-11-482, Sep. 2011.
[12] Video Quality Experts Group (VQEG), “Report on the Validation of Video Quality Models for High Definition Video Content,” June 2010, http://www.vqeg.org/
[13] K. Seshadrinathan, R. Soundararajan, A. C. Bovik and L. K. Cormack, "Study of Subjective and Objective Quality Assessment of Video", IEEE Transactions on Image Processing, vol.19, no.6, pp.1427-1441, June 2010.
[14] A. K. Moorthy, L. K. Choi, A. C. Bovik and G. de Veciana, "Video Quality Assessment on Mobile Devices: Subjective, Behavioral, and Objective Studies," IEEE Journal of Selected Topics in Signal Processing, vol. 6, no. 6, pp. 652-671, Oct. 2012.
[17] TensorFlow. https://www.tensorflow.org/








 { stamos(); }")